Main Menu
Powered by <TEI:TOK>
Maarten Janssen, 2014-
TEITOK Help Pages
Facsimile Alignment
Facsimile-based corpora are, as the term suggests, based on transcriptions of facsimile images. TEITOK offers the option to align the transcription with the original image, and then provides several ways to exploit that alignment. Alignment can be done at any level, but the base levels are page, line, and word.
The alignment per page simply keeps the link of facsimile image element in the text, and will show the image to the right of the text in the text view.
For the alignment per line, TEITOK keeps a so-called bounding box on each element, which indicates which part of the facsimile image indicated on the preceding corresponds to that line. Apart from simply highlighting part of the facsimile image in the text view, this also allows for a more intergrated representation, in which the transcription of each manuscript line is show below the corresponding facsimile cut-out. An illustration of this is given below, giving a screenshot taken from a demo corpus showing the transcription in TEITOK of the first page of the the Junius 11 manuscript, located the Bodleian library in Oxford.
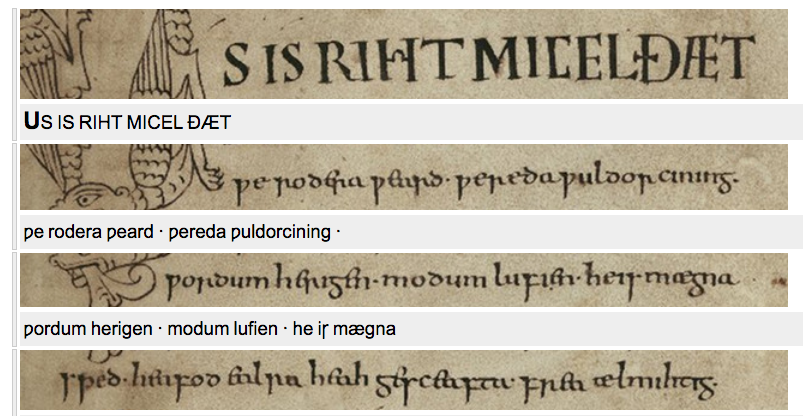
Screenshot from the Junius 11 demo corpus
It is also possible to transcribe directly in TEITOK in a line-by-line fashion; the interface for this is similar to the line view shown above, but the text is editable. The fact that the transcription is done directly below the actual image makes transcribing much more reliable given the direct visual feedback; and in later stages, it makes it much easier to spot transcription errors, which can easily be corrected.
It is also possible to take it one step further, and provide an alignment at word-level, which places a bounding box on each word. Although it is possible to do this by hand, it is meant for OCR or HTR documents, converted from hOCR or PAGE/XML to TEITOK, which will keep the bounding boxes assigned by the OCR tool on each token. With a word-level alignment, it is possible to directly look for facsimile images of words - as for instance in this example from a demo corpus containing the Ridder Knevelbaard, which show all occurrences of the word "Ridder" in the text.
Back to index